Generative AI MCQs Test – Ace your data science interviews & exams with 20 key multiple-choice questions on Generative AI! Covering LLMs, GANs, ChatGPT, Data Visualization, SQL prompts, Copilot, DataRobot, and more. Perfect for data scientists, analysts, and statisticians preparing for AI/ML assessments. Test your knowledge by taking the Quiz Generative AI MCQs Test now!
Online Generative AI MCQS Test with Answers
Online Generative AI MCQs Test with Answers
Which of the following features in data analysis plots a pair plot consisting of an analysis of all pairs of data attributes?
How can you use visualization in a generative AI tool to verify outliers?
Which prompt will generate the following query: SELECT COUNT(*) FROM Boston_house_prices
Which tool is an embeddable analytics conversational chat service that enables business users to explore data for insights using natural language inquiries?
Which of the following techniques of model consideration can improve interpretability?
Which of the following is an organizational challenge while using generative AI?
Which Python-based tool can interact with large language models (LLMs) like ChatGPT to create interactive and customizable dashboards?
Which storytelling aspect provides the data perspective to explain its relevance to the goals?
Which feature of Copilot enables correlations and new formulae in Excel?
Which is the best definition of generative AI?
How does generative AI solve the challenge of limited data availability?
How does generative AI help in creating interactive visualizations and storytelling?
DataRobot uses which Generative AI technique to provide comprehensive training data?
How does generative AI help in transforming data representation?
How does Generative AI contribute to addressing the challenges faced by data scientists, researchers, and analysts when exploring significant data patterns and insights?
Imagine you are working with generative AI to create new instances of data that resemble your original dataset’s patterns. Which model would you choose as the foundational deep learning approach for this task?
What is Generative AI?
Which of the following is a popular Generative AI model for text generation?
What does “LLM” stand for in Generative AI?
Which technique is commonly used in Generative AI for image creation?
Discover key differences between SAS functions and procedures, when to use SUM() vs. ‘+’ operator, and INPUT vs. INFILE statements in SAS Software. Learn with clear examples and practical use cases for efficient data analysis. Perfect for SAS beginners and professionals!
Table of Contents
What is the difference between SAS Functions and Procedures?
The SAS Functions and Procedures (PROCs) serve different purposes and operate in distinct ways. The breakdown of the key differences between SAS Functions and Procedures is:
SAS Functions
Perform computations or transformations on individual values (usually within a DATA step). The SAS Functions are used to (i) operate on single values or variables, (ii) return a single result for each function call, and (iii) are often used in assignment statements or expressions.
## SAS Functions Example
data example;
x = SUM(10, 20, 30); /* Returns 60 */
y = UPCASE('hello'); /* Returns 'HELLO' */
z = SUBSTR('SAS Programming', 1, 3); /* Returns 'SAS' */
run;
The following are some important types of SAS Functions:
Numeric Functions (e.g., SUM(), MEAN(), ROUND())
Character Functions (e.g., UPCASE(), SUBSTR(), TRIM())
SAS procedures, or PROCs, are used to perform data manipulation, analysis, or reporting on entire datasets. The usage of PROCS is to (i) operate on entire datasets (not just single values), (ii) generate tables, reports, graphs, or statistical analyses, and (iii) execute in a PROC step, not a DATA step.
## SAS Procedures (PROCs) Examples
proc means data=sashelp.class; /* Computes summary statistics */
var age height weight;
run;
proc sort data=sashelp.class; /* Sorts a dataset */
by descending age;
run;
proc freq data=sashelp.class; /* Generates frequency tables */
tables sex age;
run;
The types of SAS Procedures are:
Data Management PROCs (e.g., PROC SORT, PROC TRANSPOSE)
What are the key differences between SAS Functions and SAS Procedures?
The following are the key differences between SAS Functions and SAS Procedures:
Feature
SAS Functions
SAS Procedures (PROCs)
Operation
Work on single values/variables
Work on entire datasets
Execution
Used in DATA steps
Used in PROC steps
Output
Returns a single value
Generates reports, tables, or datasets
Examples
SUM(), UPCASE(), SUBSTR()
PROC MEANS, PROC SORT, PROC FREQ
Usage Context
Calculations within a variable
Dataset processing & analysis
Describe when to use SAS Functions or SAS PROCs
Use Functions when you need to transform or compute values within a DATA step.
Use Procedures when you need to analyze, summarize, or manipulate entire datasets.
What is the Difference Between the “Sum” Function and using the “+” Operator in SAS?
In SAS, both the SUM function and the + Operators can be used to perform addition, but they behave differently in terms of handling missing values and syntax. The breakdown of the differences between the SUM Function and the + Operator is:
SUM Function (SUM())
The SUM Function is used to add values while ignoring missing values (.). The general syntax of the SUM Function in SAS is
sum(var1, var2, var3, ...)
The behaviour of the SUM() is that if any argument is non-missing, the result is the sum of non-missing values. If all arguments are missing, the result is missing (.). The SUM() Function is best for
Summing multiple variables where some may have missing values.
Avoiding unintended missing results due to missing data.
## SAS SUM() Function Example
data example;
a = 10;
b = .; /* missing */
c = 30;
sum_result = sum(a, b, c); /* 10 + 30 = 40 (ignores missing) */
run;
+ Operator
The ‘+’ operator performs arithmetic addition but propagates missing values. The general syntax of the ‘+’ operator in SAS is
var1 + var2 + var3
The behaviour of ‘+’ is:
If any variable is missing, the result is missing (.).
Only works if all values are non-missing.
The use of ‘+’ operator is best for:
Cases where missing values should make the result missing (e.g., strict calculations).
## + Operator Example
data example;
a = 10;
b = .; /* missing */
c = 30;
plus_result = a + b + c; /* 10 + . + 30 = . (missing) */
run;
What are the Key Differences between the SUM() Function and the ‘+’ Operator in SAS?
Feature
SUM Function (SUM())
+ Operator
Handling Missing Values
Ignores missing values (10 + . = 10)
Returns missing if any value is missing (10 + . = .)
Syntax
sum(a, b, c)
a + b + c
Use Case
Summing variables where some may be missing
Strict arithmetic (missing = invalid)
Performance
Slightly slower (function call)
Faster (direct operation)
When to Use the SUM() Function and ‘+’ Operator in SAS?
Use SUM() when:
You want to ignore missing values (e.g., calculating totals where some data is missing).
Example: total = sum(sales1, sales2, sales3);
Use + when:
Missing values should make the result missing (e.g., strict calculations where all inputs must be valid).
Example: net_pay = salary + bonus; (if bonus is missing, net_pay should also be missing).
What is the difference between the INPUT and INFILE statements?
In SAS, both the INPUT and INFILE statements are used to read data, but they serve different purposes and are often used together. Here’s a breakdown of their differences:
INFILE Statement
The INFILE Statement in SAS specifies the source file from which data is to be read. It is used to
Defines the external file (e.g., .txt, .csv, .dat) to be read.
Can include options to control how data is read (e.g., delimiters, missing values, encoding).
The general Syntax of the INFILE Statement in SAS is:
INFILE "file-path" <options>;
The Key Options of the INFILE Statement are:
DLM=’,’ (specifies delimiter, e.g., CSV files)
DSD (handles quoted values and missing data correctly)
FIRSTOBS=2 (skips the first line, e.g., headers)
MISSOVER (prevents SAS from moving to the next line if data is missing)
## INFILE Statement Example
DATA sample;
INFILE "/path/to/data.csv" DLM=',' DSD FIRSTOBS=2;
INPUT name $ age salary;
RUN;
INPUT Statement
The INPUT Statement defines how SAS reads raw data (variable names, types, and formats). It is used to
Maps raw data to SAS variables (numeric or character).
Specifies the layout of the data (column positions, delimiters, or formats).
The general Syntax of the INPUT Statement is
INPUT variable1 $ variable2 variable3 ...;
The types of Input Styles are:
List Input (space/comma-delimited): INPUT name $ age salary;
Column Input (fixed columns): INPUT name $ 1-10 age 11-13 salary 14-20;
Formatted Input (specific formats): INPUT name $10. age 2. salary 8.2;
## INPUT Statement Example
DATA sample;
INFILE "/path/to/data.txt";
INPUT name $ age salary;
RUN;
In this post, we will discuss Type I Type II error examples from real-life situations. Whenever sample data is used to estimate a population parameter, there is always a probability of error due to drawing an unusual sample. Two main types of error occur in hypothesis tests, namely type I and type II Errors.
Table of Contents
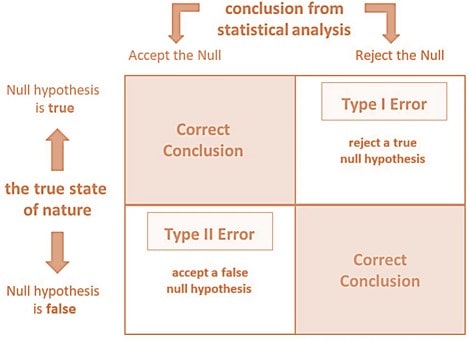
Type I Error (False Positive)
It is rejecting the null hypothesis ($H_0$) when it is actually true. The probability of Type I Error is denoted by $\alpha$ (alpha). The most common values for type I error are: 0.10, 0.05, and 0.01, etc. The example of Type I Error: A medical test indicates a person has a disease when they actually do not.
Type II Error (False Negative)
Type II Error is failing to reject the null hypothesis ($H_0$) when it is actually false. The probability of Type II Error is denoted by $\beta$ (beta). The power of the test is denoted by $1-\beta$, which is the probability of correctly rejecting a false null hypothesis. The example of a Type II error is: A medical test fails to detect a disease when the person actually has it.
Comparison Table
Error Type
What Happens
Reality
Risk Symbol
Type I
Reject H₀ when it is true
$H_0$ is true
$\alpha$
Type II
Fail to reject $H_0$ when it is false
$H_1$ (alternative) is true
$\beta$
$H_0$ True
$H_0$ False
$H_0$ Rejected
Type I Error
Correct Decision
$H_0$ Not Rejected
Correct Decision
Type II Error
Type I Type II Error Example (Real-Life Examples)
Medical Testing
Type I Error (False Positive): A healthy person is diagnosed with a disease. It may lead to unnecessary stress, further tests, or even treatment.
Type II Error (False Negative): A person with a serious disease is told they are healthy. It may delay treatment and worsen health outcomes. In this case, the more severe error is a Type II error, because missing a true disease can be life-threatening.
Court Trial (Justice System)
Type I Error: An innocent person is found guilty. It leads to punishing someone who did nothing wrong.
Type II Error: A guilty person is found not guilty. It led to the criminal going free. In this example, the more severe is often Type I, because the justice system typically aims to avoid punishing innocent people.
Fire Alarm System
Type I Error: The alarm goes off, but there’s no fire. Therefore, a false alarm causes panic and interruption.
Type II Error: There is a fire, but the alarm does not go off. It can cause loss of life or property. The more severe error is Type II error, due to the potential deadly consequences.
Spam Email Filter
Type I Error: A legitimate email is marked as spam. It means one will miss important messages.
Type II Error: A spam email is not caught and lands in your inbox. The spam email may be a minor annoyance or a potential phishing risk. The more severe error in this case is usually Type I, especially if it causes loss of critical communication (like job offers, invoices, etc.).
Quality Control in Manufacturing
A factory tests whether its products meet safety standards. The null hypothesis ($H_0$) states that the product meets requirements, while the alternative ($H_1$) claims it is defective.
Type I Error (False Rejection): If a good product is mistakenly labeled defective, the company rejects a true null hypothesis ($H_0$), leading to unnecessary waste and financial loss.
Type II Error (False Acceptance): If a defective product passes inspection, the company fails to reject a false null hypothesis ($H_0$). This could result in unsafe products reaching customers, damaging the brand’s reputation.
Which Error is More Severe?
It depends on the context.
In healthcare or safety, Type II errors are often more dangerous.
In justice or decision-making, Type I errors can be more ethically concerning.
Designing a good hypothesis test involves balancing both types of errors based on what’s at stake.