Table of Contents
Introduction to Multiple Regression Model
A multiple regression model (a regression having multi-variable) is referred to as a regression model having more than one predictor (independent and explanatory variable) to explain a response (dependent variable). We know that simple regression models have one predictor used to explain a single response, while in the case of multiple (multivariable) regression models, more than one predictor in the models. Simple regression models and multiple (multivariable) regression models can further be categorized as linear or non-linear regression models.
Note that linearity is not based on predictors or the addition of more predictors in the simple regression model; it is referred to as the parameter of variability (parameters attached to predictors). If the parameters of variability have a constant rate of change, then the models are referred to as linear models, whether it is a simple regression model or multiple (multivariable) regression models. It is assumed that the relationship between variables is considered linear, though this assumption can never be confirmed in the case of multiple linear regression.
However, as a rule, it is better to look at a bivariate scatter diagram of the variable of interest, you check that there should be no curvature in the relationship. A scatter matrix plot is a more useful visualization between variables of interest.
The multiple regression model also allows us to determine the overall fit (which is known as variance explained) of the model and the relative contribution of each of the predictors to the total variance explained (overall fit of the model). For example, one may be interested to know how much of the variation in exam performance can be explained by the following predictors such as revision time, test anxiety, lecture attendance, and gender, “as a whole”, but also the “relative contribution” of each independent variable in explaining the variance.
General Form of Multiple Regression Model
A multiple regression model has the form
\[y=\alpha+\beta_1 x_1+\beta_2 x_2+\cdots+\beta_k x_k+\varepsilon\]
Here $y$ is a continuous variable and $x$’s are known as predictors, which may be continuous, categorical, or discrete. The above model is referred to as a linear multiple (multivariable) regression model.
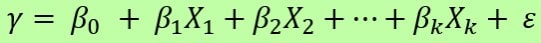
Example of Multiple Regression Model
For example prediction of college GPA by using high school GPA, test scores, time given to study, and rating of high school as predictors.
- How rainfall, temperature, and the amount of fertilizer impact and affect crop growth
- Influence of various factors (such as cholesterol, blood pressure, or diabetes) on health outcomes
- Blood pressure depends on variables, for example, gender, age, height, weight, exercise, diet, and medication.
- The Weight of a person is linearly related to their height and age.
- Studying the effect of education, gender, and profession on income.
- The price of a house depends on the size of the house, the number of rooms, the community, the facilities available, etc.
Assumptions of the Multiple Regression Model
Multiple regression models also have some assumptions that need to be followed or fulfilled. For example, the residuals should be normally distributed. There should be no collinearity/ multicollinearity among the regressors/ independent variables. The variance of error terms should be homoscedastic, and error terms should not be correlated (no autocorrelation).
Common Applications of Multiple Regression Models
- Marketing: Predicting customer spending based on factors like income, gender, age, and advertising exposure.
- Social Science: Analyzing the factors that influence voting behavior, such as gender, education level, income, and political party affiliation.
- Finance: Estimating stock prices based on company earnings, economic indicators, and market trends.
- Predicting house prices: One can use factors like square area, number of bedrooms, and location to predict the selling price of a house.
- Identifying risk factors for diseases: Researchers can use multiple regression to see how lifestyle choices, genetics, and environmental factors contribute to the risk of developing a particular disease.
Read Assumptions of Multiple Regression Model


