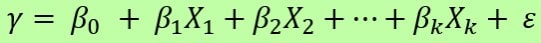Introduction to Multiple Regression Analysis
Francis Galton (a biometrician) examines the relationship between fathers’ and sons’ height. He analyzed the similarities between the parent and child generation of 700 sweet peas. Galton found that the offspring of tall parents tended to be shorter and offspring of shorter parents tended to be taller. The height of the children depends ($Y$) upon the height of the parents ($X$). In case, there is more than one independent variable (IV), we need multiple regression analysis (MRA), also called multiple linear regression (MLR).
Table of Contents
Multiple Linear Regression Model
The linear regression model (equation) for two independent variables (regressors) is
$$Y_{ij} = \alpha + \beta_1 X_{1i} + \beta_2 X_{2i} + \varepsilon_{ij}$$
The general linear regression model (equation) for $k$ independent variables is
$$Y_{ij} = \alpha + \beta_1 X_{1i} + \beta_2 X_{2i} + \beta_3X_{3i} + \cdots + \varepsilon_{ij}$$
The $\beta$s are all regression coefficients (partial slopes) and the $\alpha$ is the intercept.
The sample linear regression model is
$$\hat{y} = \hat{\alpha} + \hat{\beta}_1 x_{1i} + \hat{\beta}_2x_{2i} + \hat{\varepsilon}_{ij}$$
Multiple Regression Coefficients Formula
To fit the MLR equation for two variables, one needs to compute the values of $\hat{\beta}_1, \hat{\beta}_2$, and $\alpha$.

The yellow part of the above formula is the (“sum of the product of 1st independent and dependent variables”) multiplied by the (“sum of the square of 2nd independent variable).
The red part of the above formula is the (“Sum of the product of 2nd independent and dependent variables”) multiplied by the (“sum of the product of two independent variables”).
The green part of the above formula is the (“sum of the square of 1st independent variable”) multiplied by the (“sum of the square of 2nd independent variable”).
The blue part of the above formula is the (“square of the sum of the product of two independent variables”).
The formula for 2nd regression coefficient is

In short, note that the $S$ stands for the sum of squares and the sum of products.
Multiple Linear Regression Example
Consider the following data about two regressors ($X_1, X_2$) and one regressand variable ($Y$).
| $Y$ | $X_1$ | $X_2$ | $X_1 y$ | $X_2 y$ | $X_1 X_2$ | $X_1^2$ | $X_2^2$ |
| 30 | 10 | 15 | 300 | 450 | 150 | 100 | 225 |
| 22 | 5 | 8 | 110 | 176 | 40 | 25 | 64 |
| 16 | 10 | 12 | 160 | 192 | 120 | 100 | 144 |
| 7 | 3 | 7 | 21 | 49 | 21 | 9 | 49 |
| 14 | 2 | 10 | 28 | 140 | 20 | 4 | 100 |
| 89 | 30 | 52 | 619 | 1007 | 351 | 238 | 582 |
\begin{align*}
S_{x_1Y} &= \sum X_1 y – \frac{\sum X_1 \sum Y}{n} = 619 – \frac{30\times 59}{5} = 265\\
S_{x_1x_2} &= \sum X_1 X_2 – \frac{\sum X_1 \sum X_2}{n} = 351 – \frac{30 \times 52}{5} = 39\\
S_{X_1^2} &= \sum X_1^2 – \frac{(\sum X_1)^2}{n} = 238 -\frac{30^2}{5} = 58\\
S_{X_2^2} &= \sum X_2^2 – \frac{(\sum X_2)^2}{n} = 582 – \frac{52^2}{5} = 41.2\\
S_{X_2 y} &= \sum X_2 Y – \frac{\sum X_2 \sum Y}{n} =1007 – \frac{52 \times 89}{5} = 81.4
\end{align*}
\begin{align*}
\hat{\beta}_1 &= \frac{(S_{X_1 Y})(S_{X_2^2}) – (S_{X_2Y})(S_{X_1 X_2}) }{(S_{X_1^2})(S_{X_2^2}) – (S_{X_1X_2})^2} = \frac{(265)(41.2) – (81.4)(39)}{(58)(41.2) – (39)^2} = 8.91\\
\hat{\beta}_2 &= \frac{(S_{X_2 Y})(S_{X_1^2}) – (S_{X_1Y})(S_{X_1 X_2}) }{(S_{X_1^2})(S_{X_2^2}) – (S_{X_1X_2})^2} = \frac{(81.4)(58) – (265)(39)}{(58)(41.2) – (39)^2} = -6.46\\
\hat{\alpha} &= \overline{Y} – \hat{\beta}_1 \overline{X}_1 – \hat{\beta}_2 \overline{X}_2\\
&=31.524 + 8.91X_1 – 6.46X_2
\end{align*}
Important Key Points of Multiple Regression
- Independent variables (predictors, regressors): These are the variables that one believes to influence the dependent variable. One can have two or more independent variables in a multiple-regression model.
- Dependent variable (outcome, response): This is the variable one is trying to predict or explain using the independent variables.
- Linear relationship: The core assumption is that the relationship between the independent variables and dependent variable is linear. This means the dependent variable changes at a constant rate for a unit change in the independent variable, holding all other variables constant.
The main goal of multiple regression analysis is to find a linear equation that best fits the data. The multiple regression analysis also allows one to:
- Predict the value of the dependent variable based on the values of the independent variables.
- Understand how changes in the independent variables affect the dependent variable while considering the influence of other independent variables.
Interpreting the Multiple Regression Coefficient