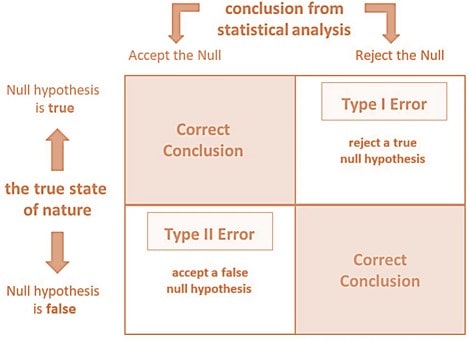
A formal hypothesis test in statistics is a structured method used to determine whether there is enough evidence in a sample of data to infer that a certain condition holds for the entire population. It involves making an initial assumption (the null hypothesis) and then evaluating whether the observed data provides sufficient evidence to reject that assumption in favor of an alternative hypothesis.
Table of Contents
Null and Alternative Hypotheses
In a formal hypothesis test, the null hypotheses are denoted by $H_o$ and the alternative hypotheses are denoted by $H_a$. The null and alternative hypotheses need to be assigned as follows:
Null Hypothesis
The null hypothesis is the hypothesis being tested. $H_o$ must
- be the hypothesis we want to reject
- contain the condition of equality (=, $\ge$, or $\le$)
Alternative Hypothesis
The alternative hypothesis is always the opposite of the null hypothesis, $H_o$. $H_a$ must
- be the hypothesis we want to support
- not contain the condition of equality (<, >, $\ne$)
A formal hypothesis test will always conclude with a decision to reject $H_o$ based on sample data or the decision that there is not strong enough evidence to reject $H_o$.

Components of a Formal Hypothesis Test
The following are key components of a formal hypothesis test.
- Null Hypothesis ($H_o$)
It is a statement of “No Effect” or “No Difference”. For example, $H_o:\mu=\mi_o$ (population mean $\mu$ equals a specified value $\mu_o$ - Alternative Hypothesis ($H_1$)
It is a statement that contradicts the null hypothesis. An alternative hypothesis can be one-tailed (for example, $H_1:\mu> \mu_o$, or $H_1:\mu<\mu_o$) or two-tailed (for instance, $H_1:\mu\ne\mu_o$). - Test Statistic (Test Formula)
- A numerical value is calculated from sample data by using an appropriate t-statistic, z-score, f-statistic, or $\chi^2$ statistic.
- Significance Level ($\alfha$)
The maximum acceptable probability is typically chosen at the outset of the hypothesis test and is referred to as the level of significance or significance level for the test. The level of significance is denoted by $\alpha$, and the most commonly used values are $\alpha = 0.10, 0.05, and 0.01$.
Note that once $\alpha$ (level of significance) is determined, the value of $\beta$ is also fixed; the probability of making a type-II error in a hypothesis test. - P-value
The probability of observing the test statistic (or more extreme) if $H_o$ is true. If $p\le\alpha$, reject $H_o$; otherwise, accept it. - Decision Rule
Reject $H_o$ if the test statistic falls in the critical region or if $p\le\alpha$ - Conclusion
State whether there is sufficient evidence to reject $H_o$ in favour of $H_1$.
Hypothetical Example: One-Sample t-test
- Null Hypothesis: The population mean $\mu=50$
- Alternative Hypothesis: The population mean $\mu \ne 50$ (two-tailed test)
- Test Statistic: $t=\frac{\overline{x}-\mu}{\frac{s}{\sqrt{n}}}$, where $\overline{x}$ is the sample mean, $s4 is the sample standard deviation, $n$ is the sample size
- Decision: if $|t| > t_{\alpha/2, n-1}$ or $p<\alpha$, reject $H_o$
Real Life Examples of Formal Hypothesis Tests
The following are a few real-life examples of formal hypothesis tests used in various fields.
- Medical Testing (Drug Efficacy): Consider a pharmaceutical company that tests whether a new drug lowers blood pressure more effectively than a placebo. It is a real case used in clinical trials for hypertension medications. The hypotheses will be
- $H_o$: The drug has no effect ($\mu_{drug} = \mu_{placebo}$.
- $H_1: The drug reduces blood pressure ($\mu_{drug}<\mu_{placebo}$). It is a one-tailed test.
- Test Statistic Used: Two-sample t-test will be used for comparing the means of two groups.
- Social Science (Opinion Polls): Consider a pollster who tests whether support for a political party candidate differs between men and women. The hypothesis may be
- $H_o:$: No gender difference in support ($p_{men} = p_{women}$).
- $H_1: Support differs by gender ($p_{men}\ne p_{p_{women}$). It is a two-tailed test.
- Test Statistic Used: Chi-Square test for independence (categorical data) will be used.
- Economics (Policy Impact): A government tests whether a tax incentive increased small business growth. The hypotheses will be
- $H_o$: The policy had no effect ($\mu_{after} – \mu_{before}=0$).
- Test Statistic use: Regression analysis with a dummy variable or difference-in-differences test.
- Business and Marketing (A/B Testing): An e-commerce company tests whether a redesigned website increases sales compared to the old version. The hypotheses will be:
- $H_o$:The new design has no impact on sales ($p_{new}=p_{old}$)
- $H_1$: The new design increases sales ($p_{new}>p_{old}$). It is a one-tailed test.
- Test Statistic: For comparing conversion rates, a two-proportion z-test can be used.
- Manufacturing (Quality Control): Suppose a factory checks if the average weight of cereal boxes meets the advertised weight of 500g. The hypotheses are:
- $H_o$: The mean weight is 500g ($\mu=500$)
- $H_1$: The mean weight differs from 500g ($\mu\ne 500$). It is a two-tailed test.
- Test Statistic: A sample t-test can be used for testing against a known standard.
- Environmental Science (Pollution Levels): Researchers are interested in testing if a river’s pollution level exceeds the safe limit (e.g., lead concentration > 15ppm). The hypotheses may be:
- $H_o$: Mean lead concentration $\le$ 15 ppm ($\mu\le 15$)
- $H_1$: Mean lead concentration > 15 ppm ($\mu > 15$). It is a two-tailed test.
- Test Statistic: One-sample t-test (or non-parametric Wilcoxon test, if data is skewed) can be used
- Education (Test Score Improvement): A school may be interested in testing whether a new teaching method improves students’ math scores. The hypothesis may be
- $H_o$: The new method has no effect ($\mu_{after} – \mu_{before}=0$)
- $H_1$: The new method improves scores ($\mu_{after} > \mu_{before}$). It is a one-tailed test.
- Test Statistic: A paired sample t-test can be used.
- Psychology (Behavioural Studies): A researcher may test whether sleep deprivation affects reaction time. The hypotheses are
- $H_o$: Sleep deprivation has no effect ($\mu_{sleep\,deprived} > u_{normal\,sleep})
- $H_1$: Sleep deprivation increases reaction time ($\mu_{sleep\,deprived}>\mu_{normal}$)
- Test Statistic: An Independent two-sample t-test can be used for comparing two groups.
Exploratory Data Analysis in R